
That is half two of a multi-part weblog sequence on AI. Half one, Why 2024 is the 12 months of AI for Networking, mentioned Cisco’s AI networking imaginative and prescient and technique. This weblog will give attention to evolving information heart community infrastructure for supporting AI/ML workloads, whereas the subsequent weblog will focus on the Cisco compute technique and improvements for mainstreaming AI.
As mentioned partially one of many weblog sequence, Synthetic intelligence (AI) and machine studying (ML) have just lately skilled a steep funding trajectory just lately, catapulted by generative AI. This has opened up new alternatives to ship actionable insights and real-world problem-solving capabilities.
Generative AI requires a big quantity of processing energy and better networking efficiency to ship outcomes quickly. Hyperscalers have led the AI revolution with mass-scale infrastructure utilizing hundreds of graphics processing models (GPUs) to course of petabytes of knowledge for AI workloads, equivalent to coaching fashions. Many organizations, together with enterprise, public sector, service suppliers, and Tier 2 web-scalers, are exploring or beginning to use generative AI with coaching and inference fashions.
To course of AI/ML workloads or jobs that contain giant information units, it’s essential to distribute them throughout a number of GPUs in an AI/ML cluster. This helps steadiness the load by means of parallel processing and ship high-quality outcomes shortly. To realize this, it’s important to have a high-performance community that helps non-blocking, low-latency, lossless material. With out such a community, latency or packet drops could cause studying jobs to take for much longer to finish, or might not full in any respect. Equally, when operating AI inferencing in edge information facilities, it’s vital to have a strong community to ship real-time insights to numerous end-users.
Why Ethernet?
The muse for many networks in the present day is Ethernet, which has developed from use in 10Mbps LANs to WANs with 400GbE ports. Ethernet’s adaptability has allowed it to scale and evolve to fulfill new calls for, together with these of AI. It has efficiently overcome challenges equivalent to scaling previous DS1, DS3, and SONET speeds, whereas sustaining the standard of service for voice and video visitors. This adaptability and resilience have allowed Ethernet to outlast alternate options equivalent to Token Ring, ATM, and body relay.
To assist enhance throughput and decrease compute and storage visitors latency, the distant direct reminiscence entry (RDMA) over Converged Ethernet (RoCE) community protocol is used to help distant entry to reminiscence on a distant host with out CPU involvement. Ethernet materials with RoCEv2 protocol help are optimized for AI/ML clusters with broadly adopted standards-based expertise, simpler migration for Ethernet-based information facilities, confirmed scalability at decrease cost-per-bit, and designed with superior congestion administration to assist intelligently management latency and loss.
In line with the Dell’oro Group, AI networks will act as a catalyst to speed up the transition to larger speeds. Market demand from “Tier 2/3 and huge enterprises are forecast to be vital, approaching $10 B over the subsequent 5 years,” and they’re anticipated to choose Ethernet.
Why Cisco AI infrastructure?
Now we have made vital investments in our information heart networking portfolio for AI infrastructure throughout platforms, software program, silicon, and optics. This embody Cisco Nexus 9000 Collection switches, Cisco 8000 Collection Routers, Cisco Silicon One, community working methods (NOSs), administration, and Cisco Optics (see Determine 1).
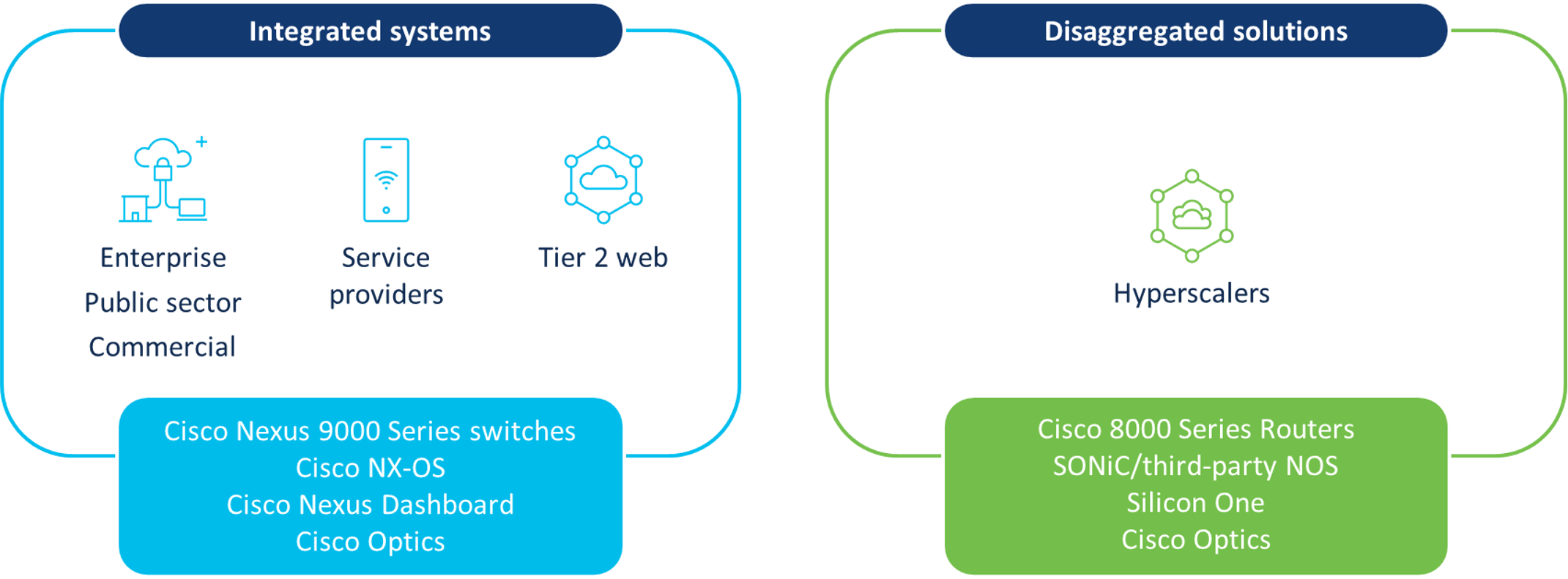
Determine 1. Cisco AI/ML information heart infrastructure options
This portfolio is designed for information heart Ethernet networks transporting AI/ML workloads, equivalent to operating inference fashions on Cisco unified computing system (UCS) servers. Prospects want selections, which is why we’re offering flexibility with completely different choices.
Cisco Nexus 9000 Collection switches are built-in options that ship high-throughput and supply congestion administration to assist scale back latency and visitors drops throughout AI/ML clusters. Cisco Nexus Dashboard helps view and analyze telemetry, and may help shortly configure AI/ML networks with automation, together with congestion parameters, ports, and including leaf/backbone switches. This resolution offers AI/ML prepared networks for patrons to fulfill the important thing necessities, with a blueprint for community infrastructure and operations.
Cisco 8000 Collection Routers help disaggregation for information heart use instances requiring high-capacity open platforms utilizing Ethernet—equivalent to AI/ML clusters within the hyperscaler phase. For these use instances, the NOS on the Cisco 8000 Collection Routers may be third-party or Software program for Open Networking within the Cloud (SONiC), which is community-supported and designed for patrons needing an open-source resolution. Cisco 8000 Collection Routers additionally help IOS XR software program for different information heart routing use instances, together with super-spine, information heart interconnect, and WAN.
Our options portfolio leverages Cisco Silicon One, which is Cisco chip innovation based mostly on a unified structure that delivers high-performance with useful resource effectivity. Cisco Silicon One is optimized for latency management with AI/ML clusters utilizing Ethernet, telemetry-assisted Ethernet, or absolutely scheduled material. Cisco Optics allow excessive throughput on Cisco routers and switches, scaling as much as 800G per port to assist meet the calls for of AI infrastructure.
We’re additionally serving to prospects with their budgetary and sustainability targets by means of {hardware} and software program innovation. For instance, system scalability and Cisco Silicon One energy effectivity assist scale back the quantity of assets required for AI/ML interconnects. Prospects can entry community visibility into precise utilization of energy and carbon footprint equivalent to KWh, value, and CO2 emissions by way of Cisco Nexus Dashboard Insights.
With this AI/ML infrastructure options portfolio, Cisco helps prospects ship high-quality experiences for his or her end-users with quick insights, by means of sustainable, high-performance AI/ML Ethernet materials which are clever and operationally environment friendly.
Is my information heart able to help AI/ML purposes?
Information heart architectures should be designed correctly to help AI/ML workloads. To assist prospects accomplish this purpose, we utilized our intensive information heart networking expertise to create a information heart networking blueprint for AI/ML purposes (see Determine 2), which discusses the right way to:
- Construct automated, scalable, low-latency, Ethernet networks with help for lossless transport, utilizing congestion administration mechanisms equivalent to express congestion notification (ECN) and precedence circulate management (PFC) to help RoCEv2 transport for GPU memory-to-memory switch of knowledge.
- Design a non-blocking community to additional enhance efficiency and allow quicker completion charges of AI/ML jobs.
- Rapidly automate configuration of the AI/ML community material, together with congestion administration parameters for quality-of-service (QoS) management.
- Obtain completely different ranges of visibility into the community by means of telemetry to assist shortly troubleshoot points and enhance transport efficiency, equivalent to real-time congestion statistics that may assist establish methods to tune the community.
- Leverage the Cisco Validated Design for Information Middle Community Blueprint for AI/ML, which incorporates configuration examples as finest practices on constructing AI/ML infrastructure.
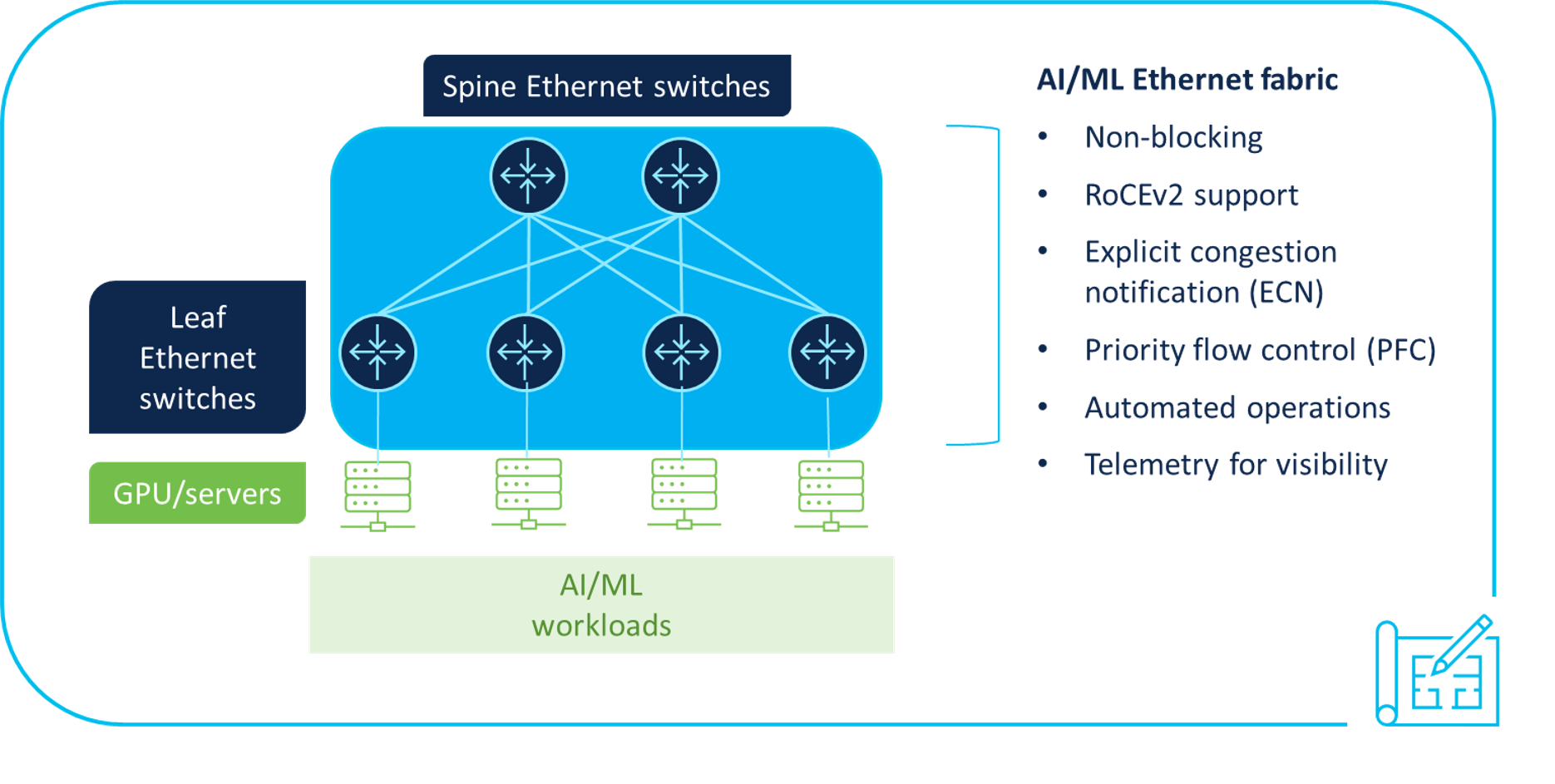
Determine 2. Cisco AI information heart networking blueprint
How do I get began?
Evolving to a next-gen information heart might not be simple for all prospects, which is why Cisco is collaborating with NVIDIA® to ship AI infrastructure options for the info heart which are simple to deploy and handle by enterprises, public sector organizations, and repair suppliers (see Determine 3).
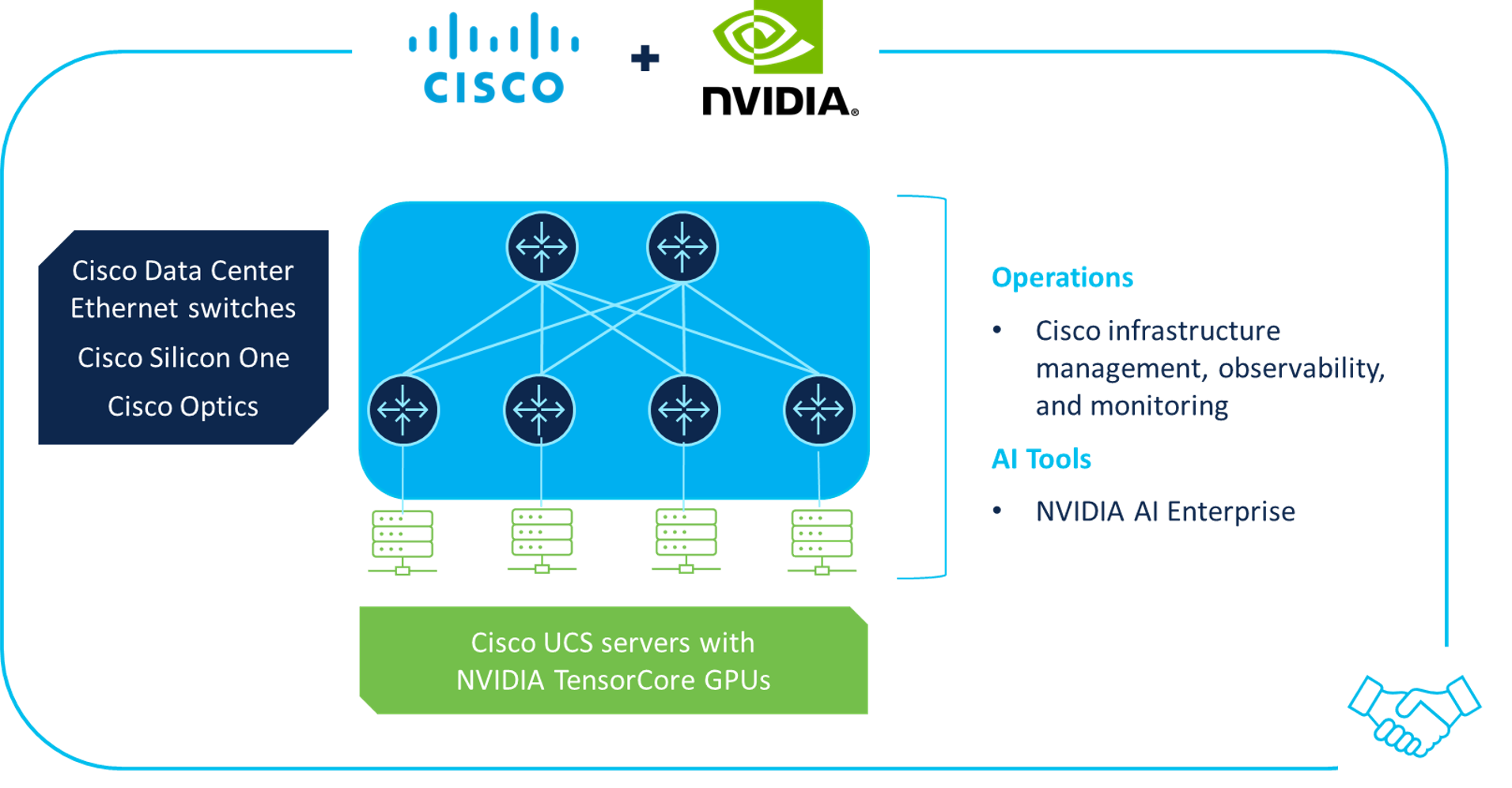
Determine 3. Cisco/NVIDIA partnership
By combining industry-leading applied sciences from Cisco and NVIDIA, built-in options embody:
- Cisco information heart Ethernet infrastructure: Cisco Nexus 9000 Collection switches and Cisco 8000 Collection Routers, together with Cisco Optics and Cisco Silicon One, for high-performance AI/ML information heart community materials that management latency and loss to allow higher experiences with well timed outcomes for AI/ML workloads
- Cisco Compute: M7 technology of UCS rack and blade servers allow optimum compute efficiency throughout a broad array of AI and data-intensive workloads within the information heart and on the edge
- Infrastructure administration and operations: Cisco Networking Cloud with Cisco Nexus Dashboard and Cisco Intersight, digital expertise monitoring with Cisco ThousandEyes, and cross-domain telemetry analytics with the Cisco Observability Platform
- NVIDIA Tensor Core GPUs: Newest-generation processors optimized for AI/ML workloads, utilized in UCS rack and blade servers
- NVIDIA BlueField-3 SuperNICs: Function-built community accelerators for contemporary AI workloads, offering high-performance community connectivity between GPU servers
- NVIDIA BlueField-3 information processing models (DPUs): Cloud infrastructure processors for offloading, accelerating, and isolating software-defined networking, storage, safety, and administration features, considerably enhancing information heart efficiency, effectivity, and safety
- NVIDIA AI Enterprise: Software program frameworks, pretrained fashions, and growth instruments, in addition to new NVIDIA NIM microservices, for safer, secure, and supported manufacturing AI
- Cisco Validated Designs: Validated reference architectures designed assist to simplify deployment and administration of AI clusters at any scale in a variety of use instances spanning virtualized and containerized environments, with each converged and hyperconverged choices
- Companions: Cisco’s international ecosystem of companions may help advise, help, and information prospects in evolving their information facilities to help AI/ML purposes
Main the best way
Cisco’s collaboration with NVIDIA goes past promoting current options by means of Cisco sellers/companions, as extra technological integrations are deliberate. By way of these improvements and dealing with NVIDIA, we’re serving to enterprise, public sector, service supplier and web-scale prospects on the info heart journeys to totally enabled AI/ML infrastructures, together with for coaching and inference fashions.
We’ll be at NVIDIA GTC, a world AI convention operating March 18–21, so go to us at Sales space #1535 to study extra.
Within the subsequent weblog of this sequence, Jeremy Foster, SVP/GM, Cisco Compute, will focus on the Cisco Compute technique and improvements for mainstreaming AI.
Discover out extra from the press launch
Share: